原文链接:https://aclanthology.org/2020.coling-main.311.pdf
intro
本文针对ASR转化成文本之后的文本分类任务进行鲁棒性研究。作者基于EBERT进行优化,EBERT比传统bert的优点在于后者只使用输入的第一个【CLS】token生成输入的表征,其余的均丢弃,可是当文本带噪时单一的【CLS】token作为表征容易受到剧烈影响。Ebert则把丢弃的token作为额外信息的来源,与第一个【CLS】token共同生成输入表征,更具鲁棒性。
作者对EBERT的优化点使用一个新的注意记忆层和多层注意层进一步编码那些本该丢弃的token,在注意包含层生成一个表征e,最终和【CLS】token的表征共同投影生成一个鲁棒性表征,优化文本分类。
method
作者模型图如下:

- inpuut的tokens编码成embedding后,过一个transformer layer编码成tokens T。
- tokens T分为两部分,一部分是【CLS】token,直接输入投影层
- 另一部分则是本该遗弃的剩余 tokens Ti∀i∈{1,…,N},这些剩余的tokens经过多头自注意力机制,生成表示d
- 表示d进入注意力包含层(Attentive Embracement Layer),通过将剩余的tokens们与【CLS】tokens进行一一比较,考虑他们与【cls】token相比较的重要性,最终生成一个个概率作为这些tokens被选择的概率,dn变为d‘n(如下图(b))
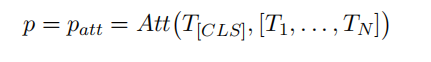
- 最终这些d‘n加和生成e,将【CLS】token与剩余token的表示e进行投影对齐,生成最终鲁棒性表示T‘c。
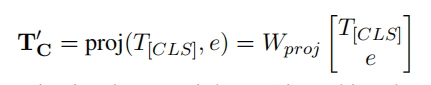
- T‘c代表句子的表征,下面的公式代表该表征被分类到类C的概率:
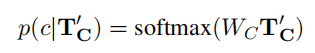
dataset
使用意图分类的ChatbotNLU评估语料库。由从一个德国电报聊天机器人中获得的句子组成,用于回答有关公共交通连接的问题。该数据集有两个意图,即【出发时间】和【查找站点的连接】。100个训练样本和106个测试样本。尽管英语是测试的主要语言,但这个数据集包含了一些德语站点和街道名称。原始数据集包含干净的数据,作者为了加入噪声,对该数据应用一个文本到语音(TTS),然后应用一个语音到文本(STT)模块。这个过程如图所示:
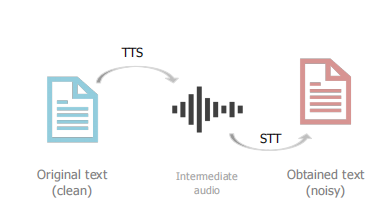
通过分别换成两个不同STT模块,生成两个不同的数据集witai和sphinx,并通过WER评估两个数据集的噪声水平。
set up
三种训练测试设置:
(1) 训练和测试干净的数据
(2) 训练干净数据和测试噪声数据
(3) 训练和测试噪声数据
experiment
主试验:
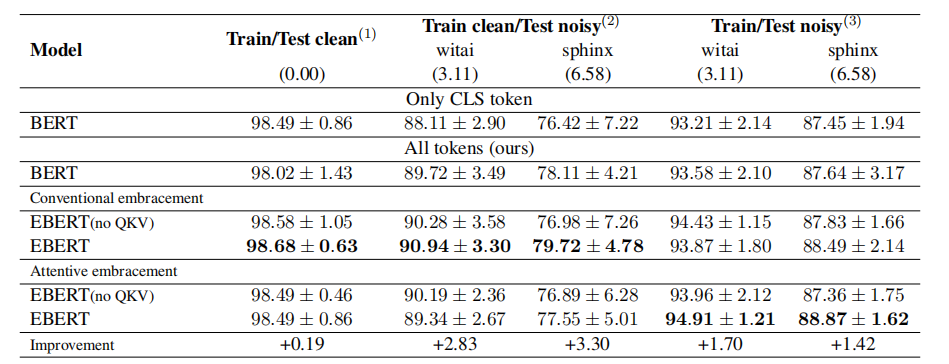
消融实验:(未仔细看)
换了四种EBERT对于剩余tokens的处理结构:
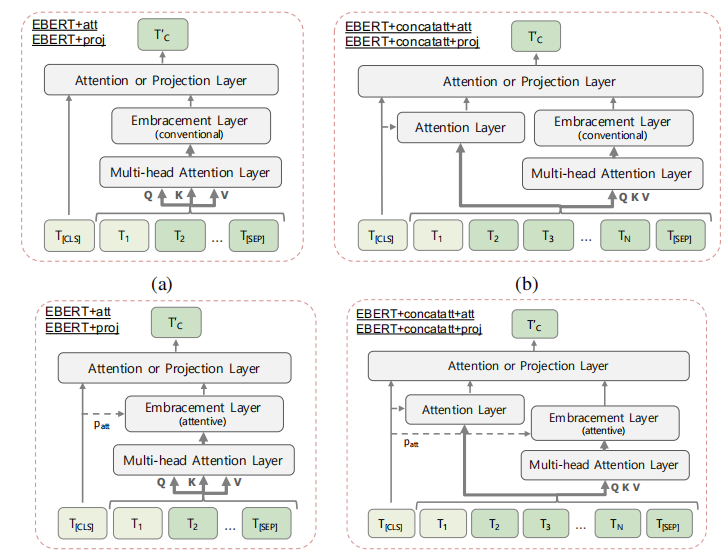
实验结果:

个人总结:感觉创新点很少,就是修改EBERT,把原本的等概率P=1/N抽取剩余的tokens,换成了通过attention输出抽取权重,但是在训练测试的设置2下,有不错的提升。

![[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记](https://img-blog.csdnimg.cn/9d909061f81a4c58a4cd7c9a0c40e1d4.png)